Este es un manual básico de: Como entrenar un Chatbot con JSON
Como entrenar un Chatbot con JSON
A continuación, te proporcionaré los archivos necesarios para entrenar un chatbot básico. Utilizaremos la biblioteca nltk para el procesamiento del lenguaje natural y tensorflow para entrenar un modelo simple. Estos son los archivos y su contenido:
Archivo intents.json
Este archivo contiene las intenciones y respuestas del chatbot.
{
"intents": [
{
"tag": "saludo",
"patterns": ["Hola", "¿Cómo estás?", "Buenos días", "Buenas tardes"],
"responses": ["¡Hola! ¿En qué puedo asistirte hoy?", "¡Hola! ¿Cómo puedo ayudarte?"]
},
{
"tag": "despedida",
"patterns": ["Adiós", "Nos vemos", "Hasta luego"],
"responses": ["¡Adiós! Que tengas un buen día.", "Hasta luego, ¡cuídate!"]
},
{
"tag": "gracias",
"patterns": ["Gracias", "Muchas gracias", "Te lo agradezco"],
"responses": ["¡De nada!", "¡Para eso estoy!", "¡No hay de qué!"]
}
]
}
No olvidéis que esta es solo una estructura básica, cuanto mas contenido hay mejores respuestas dará su Catbot.
Archivo entrenar.py
Este script entrenará el modelo del chatbot.
import json
import numpy as np
import random
import nltk
from nltk.stem import WordNetLemmatizer
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
from tensorflow.keras.optimizers import SGD
import pickle
lemmatizer = WordNetLemmatizer()
nltk.download('punkt')
nltk.download('wordnet')
words = []
classes = []
documents = []
ignore_words = ['?', '!', '.']
data_file = open('intents.json').read()
intents = json.loads(data_file)
for intent in intents['intents']:
for pattern in intent['patterns']:
w = nltk.word_tokenize(pattern)
words.extend(w)
documents.append((w, intent['tag']))
if intent['tag'] not in classes:
classes.append(intent['tag'])
words = [lemmatizer.lemmatize(w.lower()) for w in words if w not in ignore_words]
words = sorted(list(set(words)))
classes = sorted(list(set(classes)))
pickle.dump(words, open('words.pkl', 'wb'))
pickle.dump(classes, open('classes.pkl', 'wb'))
training = []
output_empty = [0] * len(classes)
for doc in documents:
bag = []
pattern_words = doc[0]
pattern_words = [lemmatizer.lemmatize(word.lower()) for word in pattern_words]
for w in words:
bag.append(1) if w in pattern_words else bag.append(0)
output_row = list(output_empty)
output_row[classes.index(doc[1])] = 1
training.append([bag, output_row])
random.shuffle(training)
training = np.array(training, dtype=object)
train_x = np.array([np.array(i[0]) for i in training], dtype='object')
train_y = np.array([np.array(i[1]) for i in training], dtype='object')
model = Sequential()
model.add(Dense(128, input_shape=(len(train_x[0]),), activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(len(train_y[0]), activation='softmax'))
sgd = SGD(learning_rate=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
hist = model.fit(np.array(train_x.tolist()), np.array(train_y.tolist()), epochs=200, batch_size=5, verbose=1)
model.save('chatbot_model.h5', hist)
Explicación
Conversión a dtype=object: Al crear el array training, lo hacemos con dtype=object para permitir listas de diferentes longitudes. Luego convertimos los arrays internos de train_x y train_y en listas de numpy arrays.
Aseguramos longitud uniforme: Convertimos las listas internas a arrays de numpy y nos aseguramos de que todos tengan la misma longitud.
Pasos a seguir
Guardar intents.json: Guarda el contenido del archivo intents.json en un archivo con el mismo nombre en tu directorio de trabajo.
Ejecutar entrenar.py: Ejecuta el script entrenar.py para entrenar el modelo y generar los archivos necesarios (chatbot_model.h5, words.pkl, y classes.pkl).
Interactuar en Jupyter Notebook: Utiliza el script chatbot.py proporcionado para interactuar con el chatbot.
Siguiendo estos pasos y asegurándote de que el código de entrenamiento se ejecute sin errores, deberías poder entrenar tu modelo correctamente y luego interactuar con él en Jupyter Notebook.
Archivo chatbot.py
Este script cargará el modelo entrenado y permitirá la interacción con el chatbot.
import json
import numpy as np
import random
import nltk
from nltk.stem import WordNetLemmatizer
from tensorflow.keras.models import load_model
import pickle
import ipywidgets as widgets
from IPython.display import display
lemmatizer = WordNetLemmatizer()
# Cargar archivos
model = load_model('chatbot_model.h5')
intents = json.loads(open('intents.json').read())
words = pickle.load(open('words.pkl', 'rb'))
classes = pickle.load(open('classes.pkl', 'rb'))
# Preprocesar entrada
def clean_up_sentence(sentence):
sentence_words = nltk.word_tokenize(sentence)
sentence_words = [lemmatizer.lemmatize(word.lower()) for word in sentence_words]
return sentence_words
def bow(sentence, words, show_details=True):
sentence_words = clean_up_sentence(sentence)
bag = [0]*len(words)
for s in sentence_words:
for i, w in enumerate(words):
if w == s:
bag[i] = 1
if show_details:
print(f"found in bag: {w}")
return np.array(bag)
def predict_class(sentence, model):
p = bow(sentence, words, show_details=False)
res = model.predict(np.array([p]))[0]
ERROR_THRESHOLD = 0.25
results = [[i, r] for i, r in enumerate(res) if r > ERROR_THRESHOLD]
results.sort(key=lambda x: x[1], reverse=True)
return_list = []
for r in results:
return_list.append({"intent": classes[r[0]], "probability": str(r[1])})
return return_list
def get_response(ints, intents_json):
tag = ints[0]['intent']
list_of_intents = intents_json['intents']
for i in list_of_intents:
if i['tag'] == tag:
result = random.choice(i['responses'])
break
return result
def chatbot_response(msg):
ints = predict_class(msg, model)
if not ints:
return "Lo siento, no te entendí. ¿Puedes intentar de nuevo?"
res = get_response(ints, intents)
return res
# Interfaz gráfica en Jupyter Notebook
conversation = widgets.Output()
def ask_from_bot(button):
msg = input_text.value
if msg:
with conversation:
print(f"User: {msg}")
res = chatbot_response(msg)
print(f"Bot: {res}")
input_text.value = ""
input_text = widgets.Text(placeholder='Escribe tu pregunta aquí...')
button = widgets.Button(description="Enviar")
button.on_click(ask_from_bot)
display(conversation, input_text, button)
Pasos para ejecutar en JupyterLab con Ubuntu
Instalar dependencias: En una celda de JupyterLab, instala las bibliotecas necesarias:
!pip install nltk tensorflow
!pip install tkCrear archivos: En la terminal de JupyterLab o usando celdas mágicas, crea los archivos intents.json, entrenar.py y chatbot.py con el contenido proporcionado.
Entrenar el modelo: Ejecuta el script entrenar.py desde una celda de JupyterLab:
!python entrenar.pyEjecutar el chatbot: Finalmente, ejecuta el script chatbot.py desde una celda de JupyterLab:
!python chatbot.pyEsto abrirá una ventana de diálogo en la que podrás escribir tus preguntas y recibir respuestas del chatbot.
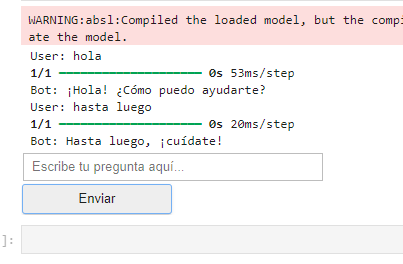
También hay que configurar: CUDA y cuDNN