¿Por qué instalar Apache Hadoop en Linux?
Apache Hadoop es una de las herramientas más populares para el manejo y procesamiento de grandes volúmenes de datos (big data). Linux, por su estabilidad y flexibilidad, es el sistema operativo ideal para instalar y ejecutar Hadoop. En esta guía, te llevaremos a través del proceso completo para instalar Apache Hadoop en Linux, desde los requisitos previos hasta la configuración final.
Requisitos previos
Antes de comenzar con la instalación, asegúrate de cumplir con los siguientes requisitos:
Sistema operativo: Distribución de Linux (Ubuntu 20.04, CentOS 7, o Debian 11).
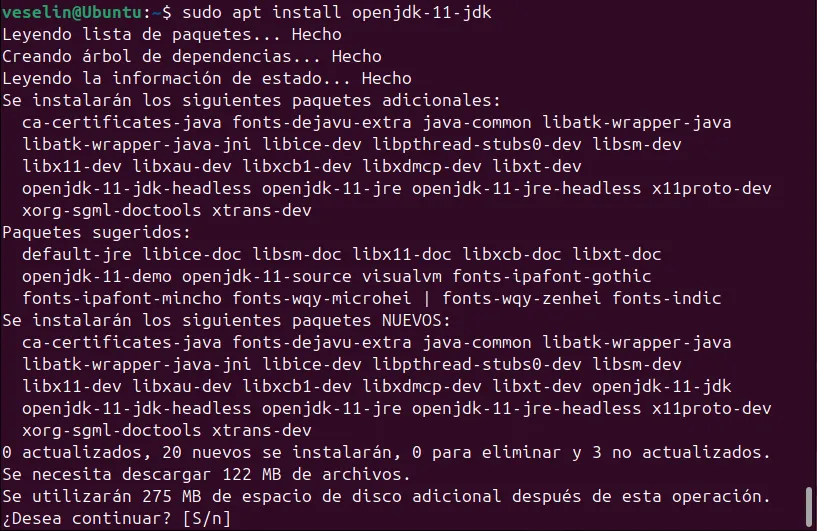
Java: Hadoop requiere Java JDK 8 o superior. Puedes instalarlo ejecutando:
sudo apt update
sudo apt install openjdk-11-jdkEspacio en disco: Mínimo 10 GB libres.
RAM: Al menos 4 GB para pruebas locales.
Paso 1: Descargar Apache Hadoop
Visita la página oficial de descargas de Apache Hadoop.
Descarga la versión estable más reciente. Por ejemplo:
wget https://downloads.apache.org/hadoop/common/hadoop-X.Y.Z/hadoop-X.Y.Z.tar.gzReemplaza X.Y.Z con la versión deseada.
Extrae el archivo descargado:
tar -xvzf hadoop-X.Y.Z.tar.gz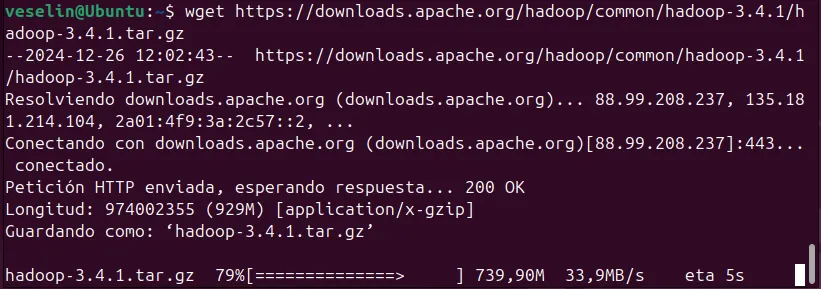
Paso 2: Configurar las variables de entorno
Para que Hadoop funcione correctamente, debes configurar las variables de entorno. Edita el archivo ~/.bashrc o ~/.zshrc y agrega las siguientes líneas:
export HADOOP_HOME=/ruta/a/hadoop-X.Y.Z
export PATH=$PATH:$HADOOP_HOME/bin
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64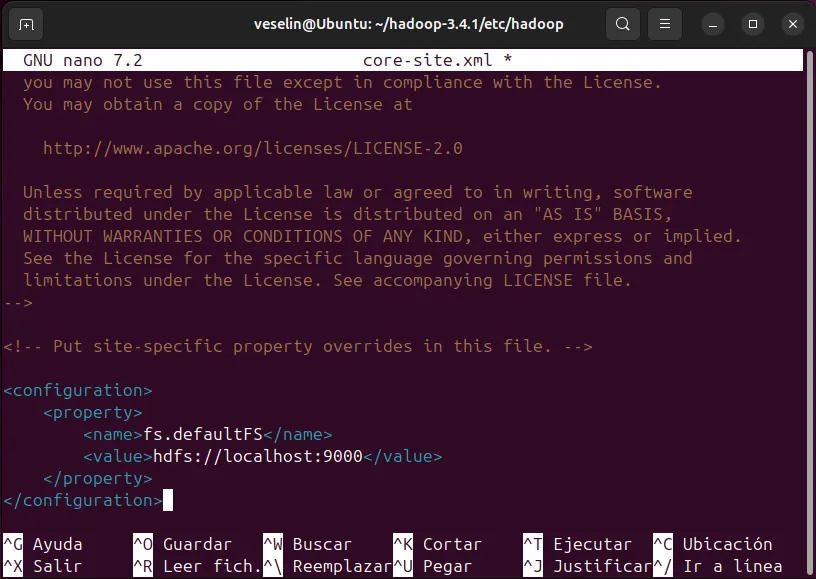
Guarda los cambios y actualiza el entorno:
source ~/.bashrcPaso 3: Configurar Hadoop en modo pseudo-distribuido
Editar el archivo core-site.xml: Navega al directorio de configuración de Hadoop:
cd $HADOOP_HOME/etc/hadoopAbre el archivo core-site.xml y agrega:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>Configurar hdfs-site.xml: Edita hdfs-site.xml y agrega:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>Configurar mapred-site.xml: Renombra el archivo de plantilla:
cp mapred-site.xml.template mapred-site.xmlLuego edítalo para incluir:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Configurar yarn-site.xml: Edita yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Paso 4: Formatear el sistema de archivos Hadoop
Antes de iniciar Hadoop, debes formatear el sistema de archivos:
hdfs namenode -formatPaso 5: Iniciar los servicios de Hadoop
Inicia el namenode y el datanode:
start-dfs.shInicia el servicio YARN:
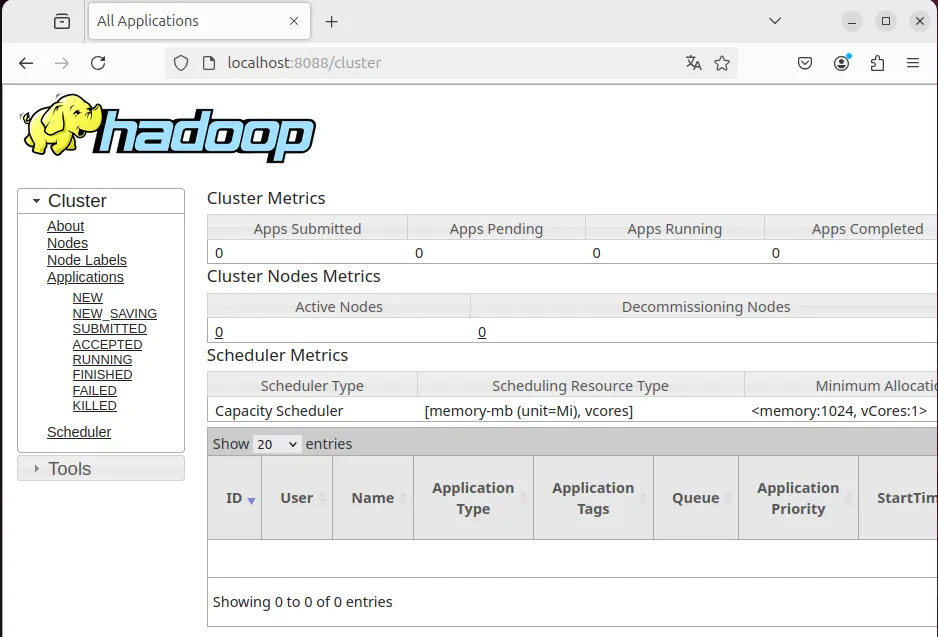
start-yarn.shPuedes verificar que los servicios están en ejecución visitando:
- Namenode: http://localhost:9870
- ResourceManager: http://localhost:8088
Resolución de problemas comunes
- Error de Java Home: Asegúrate de que
JAVA_HOMEesté correctamente configurado enhadoop-env.sh. - Permisos insuficientes: Usa
sudopara resolver problemas relacionados con permisos de directorios.
Conclusión
Con esta guía, has aprendido a instalar Apache Hadoop en Linux y configurarlo para un entorno pseudo-distribuido. Esto es solo el comienzo; desde aquí puedes escalar tu configuración a clústeres completos y comenzar a procesar grandes volúmenes de datos.